





 Ett eget chip i 14 nm ger Teslas bilar 21 gånger mer beräkningskraft för självkörning. På ett investerarmöte bjöd chefskonstruktören Pete Bannon på flera spännande detaljer om den nya självkörningsdator som alla Teslas modeller nu tillverkas med eller kan uppgraderas i efterskott till.
Ett eget chip i 14 nm ger Teslas bilar 21 gånger mer beräkningskraft för självkörning. På ett investerarmöte bjöd chefskonstruktören Pete Bannon på flera spännande detaljer om den nya självkörningsdator som alla Teslas modeller nu tillverkas med eller kan uppgraderas i efterskott till.
Den nya datorn kallas för Tesla FSD (Full Self Drive) och ersätter den nuvarande datorn HW 2.5 (Hardware 2.5). Komponentkostnaden är 20 procent lägre, energiförbrukningen är 26 procent högre och de totala beräkningsprestandan var 21 gånger högre, i en jämförelse där FSD kunde analysera 2300 videobilder per sekund mot 110 för HW 2.5, när de båda körde samma algoritm.
21 gånger mer beräkningskraft till Teslornas neuronnät kommer att göra dem smartare. Bland deras uppdrag finns allt från att identifiera vägmärken, trafikanter, filmarkeringar och så kallad körbar yta, till att upptäcka att en fotgängare är på väg att kliva ut i körbanan eller att en bil är på väg att byta fil.
Tesla är ett av många företag som utvecklar kretsar för artificiella neuronnät just nu. Elektroniktidningen presenterar då och då en översikt av sådana chips, den senaste kan du läsa här (länk).
 Självkörningsdatorn FSD ersätter den nuvarande datorn HW 2.5. På kortet sitter två egenutvecklade identiska processorer som parallellt gör samma beräkningar på samma data och jämför sina resultat för att göra systemet mer robust. Självkörningsdatorn FSD ersätter den nuvarande datorn HW 2.5. På kortet sitter två egenutvecklade identiska processorer som parallellt gör samma beräkningar på samma data och jämför sina resultat för att göra systemet mer robust.
|
 Kretsen mäter 37,5 x 37,5 mm och har 2116 BGA-kulor.
Kretsen mäter 37,5 x 37,5 mm och har 2116 BGA-kulor. I kapseln hittar du ett 14 nm-chip på 260 mm
I kapseln hittar du ett 14 nm-chip på 260 mm Chipet har 6 miljarder transistorer fördelade på 250 miljoner grindar i sin tur fördelade på kärnor för bland annat grafik, cpu:er, videokomprimering, bildbehandling, gränssnitt, kodautentisering och ...
Chipet har 6 miljarder transistorer fördelade på 250 miljoner grindar i sin tur fördelade på kärnor för bland annat grafik, cpu:er, videokomprimering, bildbehandling, gränssnitt, kodautentisering och ...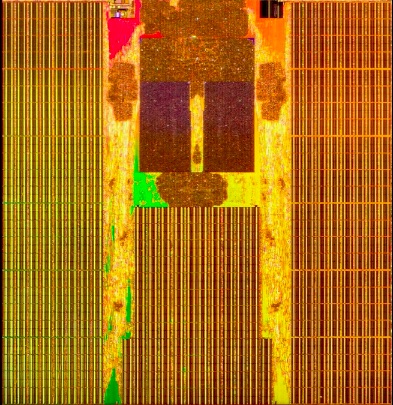
Alla sådana chips höjer just nu prestandan på neuronnätsinferenser dramatiskt. Detta är normalt eftersom utvecklingen befinner sig i övergången från att använda generella cpu:er, dsp:er eller gpu:er till att använda asicar som är skräddarsydda från början för uppgiften.
Så när chefsarkitekten Pete Bannon myste under Teslas investerarmöte i måndags kväll att han aldrig förr varit med om att utveckla ett chip som ökat prestanda med mer än en faktor tre mot sin föregångare, betyder det i översättning att han inte varit med om övergången från en generell processor till en skräddarsydd processor förut. En faktor 21 är ett strålande jobb, men inte häpnadsväckande.
Neuronnätsberäkningar består huvudsakligen av matrisoperationer – i Teslas fall till 99,7 procent – vilket är vad chipet är optimerat för. Det använder heltalsaritmetik vilket är effektivare än flyttalsaritmetik och det använder ner till åtta bitars precision, vilket AI-forskarna tror är tillräckligt.
Genom att bara arbeta i åtta bitar vinner Tesla prestanda mot Nvidia som också bygger självkörningsdatorer men i sin närmaste motsvarande modell Pegasus använder 16 bitars precision och dessutom flyttal.
På chipet finns också hårdvarustöd för ytterligare operationer som är specifika för neuronnät, som så kallad pooling och för den så kallade aktiveringsfunktion som appliceras innan en neuron levererar sin utsignal. Alla Teslas neuronnät använder den enkla aktiveringsfunktion som kallas ReLU och helt enkelt motsvarar likriktning – om utsignalen är negativ sätts den till noll.
Teslas chip och dator är närmare bestämt skräddarsydda för Teslas bilar och för självkörning vilket Tesla hävdar ger Tesla bättre optimeringsförutsättningar än Nvidia som är den som idag dominerar hårdvaran i självkörande bilar.
– Det gör livet mycket enklare när man bara har en enda kund, sade Pete Bannon när han presenterade sin grupps verk på ett investerarmöte i måndags.
Chipet är optimerat för minimal fördröjning för att ge bilen snabba reaktioner, och hanterar därför en bild i taget till skillnad från exempelvis Googles motsvarande inferenschip i molnet som är som effektivast när den kan samla 256 uppdrag innan den processar dem alla i ett och samma batchjobb.
– Minimal fördröjning är detsamma som maximal säkerhet, sade Pete Bannon.
Pete Bannon rekryterades från Apple i februari 2016. Han berättar under mötet att han redan då fick rollen som chefskonstruktör.
Teslas krav på Pete Bannon var att FSD-datorn skulle dra högst 100 watt och ha en beräkningskraft på 50 Tops. Resultatet blev närmare bestämt 72 watt och lika många Tops.
Du kan också se Tesla ange det dubbla, 144 Tops, eftersom datorn har två identiska chip som tar emot samma data och oberoende kör samma mjukvara, för redundans. De två chipen har också egna separata minneschips och strömförsörjning.
15 watt används sammanlagt av de fyra neuronkärnorna. Om Elektroniktidningen tänker rätt och inte blandar bort sig i alla dubbleringar av chips, neuronkärnor och watt, har Tesla därmed en verkningsgrad i sina neuronkärnor på 144/15 Tops/watt det vill säga tio Tops/watt, om du slår samman de två redundanta systemens prestanda. Det är siffror i toppskiktet jämfört med andra aktuella kärnor för inferenser.
För systemet som helhet ska hela FSD-kortet dra 72 watt. Det betyder i så fall att FSD som helhet levererar 2 Tops/watt (bortsett från Tops-bidragen från cpu och gpu som är jämförelsevis små). Som jämförelse drar Nvidias självkörningsdator Pegasus 500 watt och levererar 320 Tops (inklusive cpu och gpu) det vill säga 0,64 Tops/watt eller en tredjedel av Tesla, med hänsyn tagen till att Pegasus skulle använda samma sorts dubblering som Tesla i sina beräkningar.
I jämförelsen med Pegasus finns mycket som är äpplen mot päron – de är optimerade för olika saker och konstruerade med olika förutsättningar. Pegasus stöder till exempel 16 och 32 bitars precision vilket kan vara bortkastat om de inte tillför någon AI-prestanda jämfört med Teslas åttabitarsnät. Likaså kan Tesla ignorera alla algoritmer kring lidardata efersom Tesla inte använder lidarsensorer.
Exakt vilka prestanda som datorerna faktiskt levererar i sina system är förstås en annan fråga, när hänsyn tas till flaskhalsar exempelvis i form av att ladda och lagra data.
Vad gäller Teslas chip är den viktiga nyheten att Teslabilars nervsystem för att bearbeta sensordata plötsligt blivit 21 gånger större.
Chipet tillverkas i 14 nm av Samsung i dess fabrik i Austin, Texas. Med sina 260 kvadratmillimeter är det 2–3 gånger större än ett mobilchip medan ett avancerat pc-grafikchip kan vara ungefär lika mycket större.
Varje chip innehåller två neuronkärnor med vardera 96 x 96 stycken MAC-enheter som var och en gör en MAC (multiply-accumulate, A = A + B x C) per klockcykel. Kärnorna har vardera 32 Mbyte SRAM för att lagra mellanresultat och detta SRAM är vad som dominerar ytan av neuronkärnorna.
Varje klockcykel skyfflas 384 byte in i SRAM och 128 byte ut ur SRAM. Det sker i 2 GHz vilket betyder att en terabyte skyfflas per sekund per neuronkärna. Samtliga neuronnät som självkörningsdatorn använder ligger permanent i dessa 32 Mbyte SRAM – de behöver alltså aldrig laddas från DRAM vilket skulle dragit tid och energi.
Artificiella neuroner använder MAC:ar till att beräkna skalärprodukter mellan sina vikter (som defeinierades under träningen av neuronnätet) och indata.
Utöver de två neuronkärnorna har chipet en grafikkärna med den ganska blygsamma prestandan 600 Gflops. Enligt Pete Bannon chansade Tesla på att GPU:n inte skulle behöva vara större än så. Algoritmerna för bildigenkänning utvecklas fortfarande i branschen och förhoppningen var att neuronkärnorna skulle kunna avlasta gpu:n med hjälp av rätt algoritmer, vilket visade sig stämma, enligt Pete Bannon.
Grafikkärnan är en licenserad standardkomponent liksom cpu:er och övriga kärnor på chipet utom neuronkärnan.
– Detta val gjorde vi för att minimera konstruktionstid och risk.
Pete Bannon valde 14 nm och inte 10 nm eftersom alla IP-kärnor som behövdes inte fanns för 10 nm när han konstruerade chipet.
Bland de licenserade kärnorna finns en 64-bitars ARM-processor med tolv Cortex A72-kärnor som körs i 2,2 GHz. Detta ger FSD 2,5 gånger mer cpu-prestanda än HW 2.5.
Kameragränssnittet kan ta emot 2,5 miljarder bildpunkter per sekund. Bilddata normaliseras i en bildbehandlingskärna innan de skickas vidare till neuronkärnorna.
Utöver videodata tar kortet indata från radar, ultraljud, IMU, GPS, kartdata, hjulrotation och rattutslag. Minnesgränssnittet är LPDDR4 i 4266 Gbit/s vilket ger en maximal bandbredd på 68 Gbyte/s.
Chipet vägrar köra kod som inte är kryptografisk signerad av Tesla. Detta verifieras i en separat kärna på chipet.
Också en liten H.265-videokomprimeringskärna finns på chipet. Den genererar videodatata till bilens skärmar och molnet.
I december 2017 fanns ett första fungerande provchip. Ett andra provchip kom i april 2018 efter modifieringar och volymproduktion startade i juli. I december började Tesla byta HW 2.5 mot FSD i anställdas bilar. Sedan mars tillverkas Model S och X med FSD och i april även Model 3. Existerande bilar kan uppgraderas.
Nästa generation av chipet är under konstruktion och ska kunna vara klart för användning om två år. Tesla hoppas den ska ha tre gånger högre prestanda.



























